
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 최솟값
- Machine Learning
- data
- nan
- insert()
- 최댓값
- elbow method
- wcss
- hierarchical_clustering
- 반복문
- DataFrame
- string
- count()
- Dictionary
- matplotlib
- list
- DataAccess
- append()
- len()
- 분류 결과표
- 덴드로그램
- Python
- analizer
- pandas
- del
- sklearn
- dendrogram
- IN
- function
- numpy
Archives
- Today
- Total
개발공부
텐서플로우를 이용한 그리드 서치하는 방법 본문
고객 정보와 해당 고객이 금융상품을 갱신했는지 안했는지의 여부에 대한 데이터가 있다.
이 데이터를 가지고 갱신여부를 예측 (분류) 하는 딥러닝을 구성해보자.
먼저 csv파일을 판다스 데이터 프레임으로 읽어온다.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('data/Churn_Modelling.csv')
df

NAN 값이 있는지 확인한다.
df.isnull().sum()
X 를 설정한다.
X = df.loc[:, 'CreditScore' : 'EstimatedSalary']
X
y를 설정한다.
y = df['Exited']
y
문자열 데이터는 숫자로 바꿔준다. (인코딩)
Gender는 레이블 인코딩한다.
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
X['Gender'] = encoder.fit_transform(X['Gender'])
X
Geography는 원 핫 인코딩 한다.
from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
ct = ColumnTransformer( [ ('encoder', OneHotEncoder(), [1]) ],
remainder= 'passthrough')
X = ct.fit_transform(X)
X
X의 첫 컬럼은 없어도 그 뒤의 두개 컬럼만으로도 Geography를 구분할 수 있으니 제거한다.
X = X[:, 1: ]
X
피처 스케일링한다. MinMaxScaler를 이용해보자.
from sklearn.preprocessing import MinMaxScaler
sc_X = MinMaxScaler()
X = sc_X.fit_transform(X)
X
데이터를 학습용과 검증용으로 나눈다. ex (train - 80%, test - 20%)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state= 0 )
이제 그리드 서치를 이용하여 최적의 파라미터를 찾아보자.
# Tuning the ANN
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import GridSearchCV
from keras.models import Sequential
from keras.layers import Dense모델링 함수 정의
def build_classifier(optimizer) :
# 모델링
model = Sequential()
model.add(Dense(units = 6, activation = 'relu', input_shape = (11,)))
model.add(Dense(units = 8, activation= 'relu'))
model.add(Dense(units = 1, activation = 'sigmoid'))
# accuracy도 추가로 확인한다.
model.compile(optimizer = optimizer, loss = 'binary_crossentropy', metrics = ['accuracy'])
return modelmodel = KerasClassifier(build_fn= build_classifier)
# 그리드서치에 이용할 파라미터들 정의
my_parameters = {'epochs' : [30, 50],
'batch_size' : [10, 20],
'optimizer' : ['adam', 'rmsprop']}그리드 서치
grid_search = GridSearchCV(estimator = model, param_grid = my_parameters, scoring = 'accuracy')
grid_search.fit(X_train, y_train)
# 최적의 파라미터 출력
grid_search.best_params_
# 그리드 서치를 했을 때 가장 높은 score 출력
grid_search.best_score_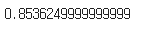
이제 가장 최적의 파라미터를 넣은 모델을 생성해서 이를 이용해 predict 하면 된다.
# 가장최적의 파라미터를 넣은 모델을 생성
model = grid_search.best_estimator_
'Python > Deep Learning' 카테고리의 다른 글
| Validation, validation_split, validation data 코드 예제 (0) | 2022.06.13 |
|---|---|
| Learning Rate를 옵티마이저에서 셋팅하는 코드 (0) | 2022.06.13 |
| 텐서플로우로 리그레션(Regression) 문제 모델링 하는 방법 실습 (0) | 2022.06.10 |
| 텐서플로우로 분류(Classification)의 문제 모델링 하는 방법 실습 (0) | 2022.06.10 |
| 텐서플로우에서 학습시 epochs 와 batch_size 이란? (0) | 2022.06.10 |
'Python/Deep Learning' Related Articles
more



